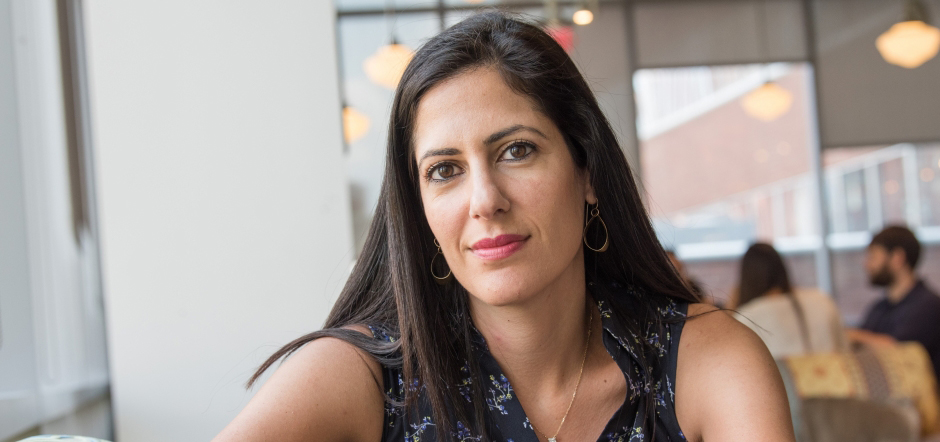Weizmann’s Dr. Tali Dekel, among the world’s leading researchers in generative AI, focuses on the hidden capabilities of existing large-scale deep-learning models. Her research with Google led to the development of the recently unveiled Lumiere
Just a few years ago, we could hardly have imagined that millions of people around the world would have access to easy-to-use generative AI applications that produce texts, images and videos. These apps can generate outputs that look as if they were created by human beings, as well as create things that have never existed in reality.
The rapid advance in the capabilities of large language models, which after decades of development have started to generate complex and reasonably credible texts, took even experts by surprise. As a result, attention also turned to models that combine text with visual data such as images and videos, and their development was fast-tracked. Now these models can generate realistic videos of a busy city street or a squirrel walking on the Moon – and all the user needs to do is input a short textual description or pictures to serve as the visual source. However, alongside these astounding capabilities and the accompanying concerns about the dangers inherent in such powerful computers, the operational range of deep learning networks is still limited – especially when it comes to video – and this is the challenge that many researchers are addressing.
The team in Dr. Tali Dekel’s laboratory for the study of computer vision in the Computer Science and Applied Mathematics Department at the Weizmann Institute of Science hope to overcome the limitations of these generative machines and bring them to the human level – or even beyond. “I define our area of research as ‘re-rendering reality,’ in other words, recreating the visual world using computational tools,” she says. “We analyze images and videos and focus on their specific aspects, and then we create a new version with different characteristics. My goal is to enhance the way that we see the world, to give us more creativity and even a new kind of interaction with the visual data.”
Adds Dekel: “Our research raises fascinating questions, such as: What does a generative model learn about the world and how does it encode this information? How can we effectively represent visual information in space and time to allow us to modify it so that we can ultimately interact with our dynamic world through videos?”
""My goal is to enhance the way that we see the world, to give us more creativity and even a new kind of interaction with the visual data"
In addition to her work at the Weizmann Institute, Dekel is also a researcher at Google. While her studies at Weizmann focus on overcoming the limitations of existing AI models, her work at Google involves developing new models, such as the groundbreaking text-to-video model Lumiere, whose output was recently unveiled to the public. Lumiere can, with the use of a short textual prompt or reference photo, produce a rich, impressive range of videos or edit existing videos. For example, the model generated a series of videos of a woman running in a park, turning her into a figure made of wooden blocks, colorful toy bricks or even flowers. When Lumiere was presented with an image of an old steam train billowing smoke on a railway track and researchers highlighted the part of the image containing the smoke, the model created a partially animated image in which only the smoke was moving. It did so in a highly realistic manner, keeping the rest of the image unchanged. Researchers even had a bit of fun with Lumiere, asking it to generate a yawning Mona Lisa and putting a smile on the girl’s face in Vermeer’s Girl with a Pearl Earring.
“Lumiere [is] a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion – a pivotal challenge in video synthesis,” according to the paper published by researchers, including Dekel, when they unveiled the new model. Lumiere is unique in its ability to generate a complete series of frames with no gaps between them, while previous models started by generating distant keyframes on the space-time scale and only then filling in the movement between the keyframes. This is why previous models had difficulty generating convincing, natural movement; Lumiere can generate entire high-quality sequences of movement.
But how do deep learning models do their magic? Even scientists are not entirely sure. “The whole field of generative AI is undergoing a paradigm shift,” Dekel explains. “In the not-so-distant past, these models were a lot smaller, simpler and designed to perform specific tasks, most often using tagged data. For example, to teach a computer to recognize objects in an image, we had to present it with a series of images in which those objects were tagged and explain to it that this is a car, this is a cat and so on. Now the models have grown and can learn from huge quantities of data without human tagging. The models acquire a universal representation of the visual world that they can use for a variety of tasks, not only the specific purpose for which they were originally trained.” And while the improvement in these models’ self-learning abilities is evident, we still do not know exactly how they work. “Large sections of neural networks are something of a ‘black box’ for us,” Dekel adds.
This enigma is especially daunting when dealing with video-generating models, since every second of video is made up of around 25 different images. In particular, most large-scale text-to-video models are very complicated, require enormous computing power and are trained on vast amounts of data. This means that the size of the computer networks and the computational challenges they face are even greater than for the models that create texts or images – and the range of the models’ impenetrable operation expands accordingly.
For Dekel, the “black boxes” inside these models provide excellent research opportunities. “During the self-learning process, the models acquire a huge amount of information about the world. As part of our research into the re-rendering of reality using digital tools, we are trying to produce different outputs from existing models, almost without altering them at all. Instead, we are trying to better understand how they work while attempting to discover new tasks that they are capable of completing,” Dekel says about research she conducted with Weizmann colleague Dr. Shai Bagon, Dr. Yoni Kasten from NVIDIA Research and Weizmann students Omer Bar-Tal, Narek Tumanyan, Michal Geyer, Rafail Fridman and Danah Yatim.
Researchers in Dekel’s lab are also looking for sophisticated methods for processing videos, which include breaking the content down into simpler components, such as an image that presents the background of a video and other images, each of which portrays objects that change in the course of the video. This separation makes the editing process much simpler: Instead of processing a massive number of pixels, the model edits only one image and all the other frames change accordingly. For example, if the color of a dress changes in one frame, the model knows how to make that change throughout the whole video, ensuring continuity. Another challenge researchers are grappling with is the fact that many images and videos generated by models do not look realistic, presenting objects that move differently from what would be expected, given our real-world experience.
As part of their efforts to teach the models how to generate videos in which movement is consistent and logical, Dekel and her team showed how the capabilities of text-to-image models can be expanded so that they can also generate and edit videos. For example, they inputted a video of a wolf moving its head from side to side into an open-source model called Stable Diffusion and asked it to generate a similar video showing a wolf-like ragdoll. At first, the model created a video that was laggy and unrealistic, since each image in the video was edited differently. But by better understanding how the model processes and represents the images during editing, the researchers managed to cause it to edit all the frames in the same manner, resulting in a video where the wolf doll moved naturally and convincingly.
Dekel recently received a €1.5 million European Research Council Starting Grant, a prestigious resource for young scientists. She intends to use the grant to further address other limitations of the models that generate and edit videos. Since video processing is such a complex task, there is a significant gap between the knowledge that a model has already gathered from the many videos on which it was trained and the specific characteristics of movement in any given video that the model is asked to generate. Dekel will try to develop a model capable of learning more about what it needs to do with a specific video from the experience it has gathered from thousands of other videos.
What about the concerns over the enormous power that these models possess? “There is a delicate balance between being aware of a technology’s potential risks and wanting to advance it further,” Dekel says. “Our commitment is to safeguard that balance. To the general public, it might sometimes appear that these models are omnipotent, but that is not currently the case. My main goal as a researcher is to expand the creative possibilities that each of us has, including people who are not professionals, and to advance science and the computational ability to see the world.”
Science Numbers
In a single pass, Google’s Lumiere generates 80frames per video sequence lasting about 3seconds, resulting in high quality and consistent videos.
On a personal note
For a scientist working in the vanguard of technology, Dekel’s scientific journey began under decidedly low-tech circumstances. She applied for her BSc studies at Tel Aviv University while traveling in India after her army service, from a café with poor internet connection. “I became interested in science and technology relatively late, when serving in the Air Force’s computer technology unit,” she says. “I ended up studying electrical engineering, which is where my passion for research started.”
Dekel eventually entered a direct track toward a PhD, earning her doctoral degree in electrical engineering and computer vision from Tel Aviv University in 2015. She then conducted postdoctoral research for two years at the Computer Science and Artificial Intelligence Lab at the Massachusetts Institute of Technology. When her postdoc advisor set up a research team at Google in Boston, she joined as a senior research scientist and worked there for four years. She continues to work for the Israeli branch of the same Google team one day a week. In 2021, at the height of the coronavirus pandemic, she returned to Israel and joined the Weizmann Institute faculty. She lives in Rehovot and has two sons, aged 10 and 8, and a 4-year-old daughter.
Dr. Tali Dekel’s research is supported by the Sagol Weizmann-MIT Bridge Program, the TVML Foundation MIT-Weizmann Collaboration Fund and the Shimon and Golde Picker - Weizmann Annual Grant.