This accomplishment started with a challenge to common wisdom, which says that every cell in an organism carries an exact duplicate of its genome. Although mistakes in copying, which are passed on to the next generation of cells as mutations, occur when cells divide, such tiny flaws in the genome are thought to be trivial and mainly irrelevant. But research students Dan Frumkin, and Adam Wasserstrom of the Biological Chemistry Department, working under the guidance of Prof. Ehud Shapiro of the Institute's Biological Chemistry, and Computer Science and Applied Mathematics Departments, raised a new possibility: Though biologically insignificant, the accumulated mutations might hold a record of the history of cell division.
Together with Prof. Uriel Feige, of the Computer Science and Applied Mathematics Department, and research student Shai Kaplan, they proved that these mutations can be treated as information and used to trace lineage on a large scale, and then applied the theory to extracting data and drafting lineage trees for living cells.
Methods employed until now for charting cell lineage trees have relied on direct observation of developing embryos. This method worked well enough for the tiny, transparent worm, C. elegans, that has around 1000 cells, all told, but for humans, with 100 trillion cells, or even newborn mice or human embryos at one month, each of which has a billion cells after some 40 rounds of cell division, the task would be impossible.
The study focused on mutations in specific, mutation-prone areas of the genome known as microsatellites. In microsatellites, a genetic 'phrase' consisting of a few nucleotides(genetic 'letters') is repeated over and over; mutations manifest themselves as additions or subtractions in length. Based on the current understanding of the mutation process in these segments, the scientists proved mathematically that microsatellites alone contain enough information to accurately plot the lineage tree for a one-billion-cell organism.
Both human and mouse genomes contain around 1.5 million microsatellites, but the team's findings demonstrated that a useful analysis can be performed based on a much smaller number. To obtain a consistent mutation record, the team used organisms with a rare genetic defect found in plants and animals alike. While healthy cells have repair mechanisms to correct copying mistakes and prevent mutation, cells with the defect lack this ability, allowing mutations to accumulate relatively rapidly.
Borrowing a computer algorithm used by evolutionary biologists that analyzes genetic information in order to place organisms on branches of the evolutionary tree, the researchers assembled an automated system that samples the genetic material from a number of cells, compares it for specific mutations, applies the algorithm to assess degrees of relatedness and from there outlines the cell lineage tree. To check their system, they pitted it against the tried and true method of observing cell divisions as they occurred in a lab-grown cell culture. The team found that, from an analysis of just 50 microsatellites, they could successfully recreate an accurate cell lineage tree.
While the research team plans to continue to test their system on more complex organisms such as mice, several scientists have already expressed interest in integrating the method into ongoing research in their fields. Says Shapiro, who heads the project: 'Our discovery may point the way to a future 'Human Cell Lineage Project' that would aim to resolve fundamental open questions in biology and medicine by reconstructing ever larger portions of the human cell lineage tree.'
Prof. Ehud Shapiro's research is supported by the M.D. Moross Institute for Cancer Research, the Dolfi and Lola Ebner Center for Biomedical Research, the Samuel R. Dweck Foundation, the Benjamin and Seema Pulier Charitable Foundation, the Robert Rees Fund for Applied Research, Dr. Mordecai Roshwald and the Estate of Klara (Haya) Seidman. Prof. Shapiro is the incumbent of the Harry Weinrebe Professorial Chair
For additional information see www.weizmann.ac.il/udi/plos2005


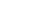


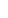











 Before and after images showing summarization with the bidirectional similarity measure. All of the relevant visual information is preserved")





 Before and after images showing summarization with the bidirectional similarity measure. All of the relevant visual information is preserved")
 Before and after images showing summarization with the bidirectional similarity measure. All of the relevant visual information is preserved")

Seeing Like a Baby
Infants soon learn to make sense of the complex world around them: Their understanding far surpasses any of the current attempts to design intelligent computerized systems. How do such young infants arrive at this understanding?
Answering this question has been a challenge for cognitive psychology researchers and computer scientists alike. On the one hand, babies cannot explain how they first learn to comprehend the world around them, and on the other, computers, for all their sophistication, need human help with labeling and sorting objects to make learning possible. Many scientists believe that for computers to “see” the world as we do, they must first learn to classify and identify objects in much the same way that a baby does.
The algorithm began with some basic insight into the stimuli that attract the attention of young infants. The scientists knew, for instance, that babies track movement from the moment they open their eyes, and that motion can be a visual cue for picking objects out of the scenery. The researchers then asked if certain types of movement might be more instructive to the infant mind than others, and whether these could provide enough information to form a visual concept. For instance, a hand makes a change in the baby’s visual field, generally by manipulating an object. Eventually the child might extrapolate, learning to connect the idea of causing-object-to-move with that of a hand. The team named such actions “mover events.”
But the model was not yet complete. With mover events, alone, the computer could learn to detect hands but still had trouble with different poses. Again, the researchers went back to insights into early perception: Infants can not only detect motion, they can track it; they are also very interested in faces. Adding in mechanisms for observing the movements of already detected hands to learn new poses, and for using the face and body as reference points to locate hands, improved the learning process.
In the next part of their study, the researchers looked at another, related concept that babies learn early on but computers have trouble grasping – knowing where another person is looking. Here, the scientists took the insights they had already gained – mover events are crucial and babies are interested in faces – and added a third: People look in the direction of their hands when they first grasp an object. On the basis of these elements, the researchers created another algorithm to test the idea that babies first learn to identify the direction of a gaze by connecting faces to mover events. Indeed, the computer learned to follow the direction of even a subtle glance – for instance, the eyes alone turning toward an object – nearly as well as an adult human.
The researchers believe these models show that babies are born with certain pre-wired patterns – such as a preference for certain types of movement or visual cues. They refer to this type of understanding as proto-concepts – the building blocks with which one can begin to build an understanding of the world. Thus the basic proto-concept of a mover event can evolve into the concept of hands and of direction of gaze, and eventually give rise to even more complex ideas such as distance and depth.
This study is part of a larger endeavor known as the Digital Baby Project. The idea, says Harari, is to create models for very early cognitive processes. “On the one hand,” says Dorfman, “such theories could shed light on our understanding of human cognitive development. On the other hand, they should advance our insights into computer vision (and possibly machine learning and robotics).” These theories can then be tested in experiments with infants, as well as in computer systems.